버퍼(buffer)란
시스템이 연산 작업을 하는데 있어 필요한 데이터를 일시적으로 메모리 상에 저장하는 공간이다.
(문자열을 처리할 것이면 문자열 버퍼가 되고, 수열이라면 숫자형 데이터 배열이 된다.)
대부분의 프로그램에서는 버퍼를 스텍에다 생성한다.
스텍은 함수 내에서 선언한 지역 변수가 저장되게 되고 함수가 끝나고 나면 반환된다.
(이것은 malloc()과 같은 반영구적인 데이터 저장 곤간과는 다른 것이다.)
buffer overflow의 동작원리
버퍼오버플로우는 미리 준비된 버퍼에 버퍼의 크기 보다 큰 데이터를 쓸 때 발생하게 된다.
40바이트의 스텍이 준비되어 있다고 가정해보자.
만약 40바이트 보다 큰 데이터를 쓰면, 버퍼가 넘치게 되고 프로그램은 에러를 발생시키게 된다.
40바이트가 아닌 41~44바이트의 데이터를 쓴다면 이전 함수의 base pointer를 수정하게 될 것이다.
더 나아가 48바이트 이상을 쓴다면 return address뿐만 아니라 그 이전에 스텍에 저장되어 있던 데이터 마저도 바뀌게 될 것이다.
여기다 시스템에게 첫 명령어를 간접적으로 내릴 수 있는 부분은 return address가 있는 위치이다.
return address는 현재 함수의 bp 바로 위에 있으므로 그 위치는 변하지 않는다. 공격자가 bp를 직접적으로 변경하지 않는다면 정확히 해당 위치에 있는 값이 EIP에 들어가게 된다. 따라서 buffer overflow 공격은 공격자가 메모리상의 임의의 위치에다 원하는 코드를 저장시켜 놓고 return address가 저장되어 있는 지점에 그 코드의 주소를 집어 넣음으로 해서 EIP에 공격자의 코드가 있는 곳의 주소가 들어가게 해 공격을 하는 방법이다.
공격자는 버퍼가 넘칠때(버퍼에 데이터를 쓸 때) 원하는 코드를 넣을 수가 있다.
물론 정확한 return address가 저장되는 곳을 찾아 정확하게 조작해 주어야 한다.
이 전에 살펴폰 simple.c (앞의 예제)를 다시 상기시켜보자. function()함수 내에서 정의한 buffer1[15]와 buffer2[10]의 버퍼가 있고 여기에는 40바이트의 버퍼가 할당되어 있다.
function() 함수 내에서는 하지 않았지만 이 버퍼에 데이터를 쓰려한다고 생각해보자.
strcpy(buffer2, receive_from_client);
이 코드를 예로 들어보자.
이코드는 client로부터 수신한 데이터를 buffer2와 buffer1에 복사한다. 알다시피 strncpy()과 같은 함수는 몇 바이트나 저장할지 지정해 주지만 strcpy함수는 길이 체크를 해 주지 않기 때문에 receive_from_client 안에 들어있는 데이터에서 NULL(\0)를 만날 때까지 복사를 한다.
이 스텍의 구조에서 45~48바이트 위치에 있는 return address도 조작해줘야 하고 공격 코드도 넣어줘야한다.

클라이언트인 공격자가 전송하는 데이터는 receive_from_client에 저장되어 버퍼에 복사될 것이다. 위의 그림과 같이 데이터가 구성되어 전송된다고 가정하자. 그리고 strcpy가 호출되어 receive_from_client가 buffer2에 복사가 될 것을 예상하면 다음과 같이 매칭 될것이다.
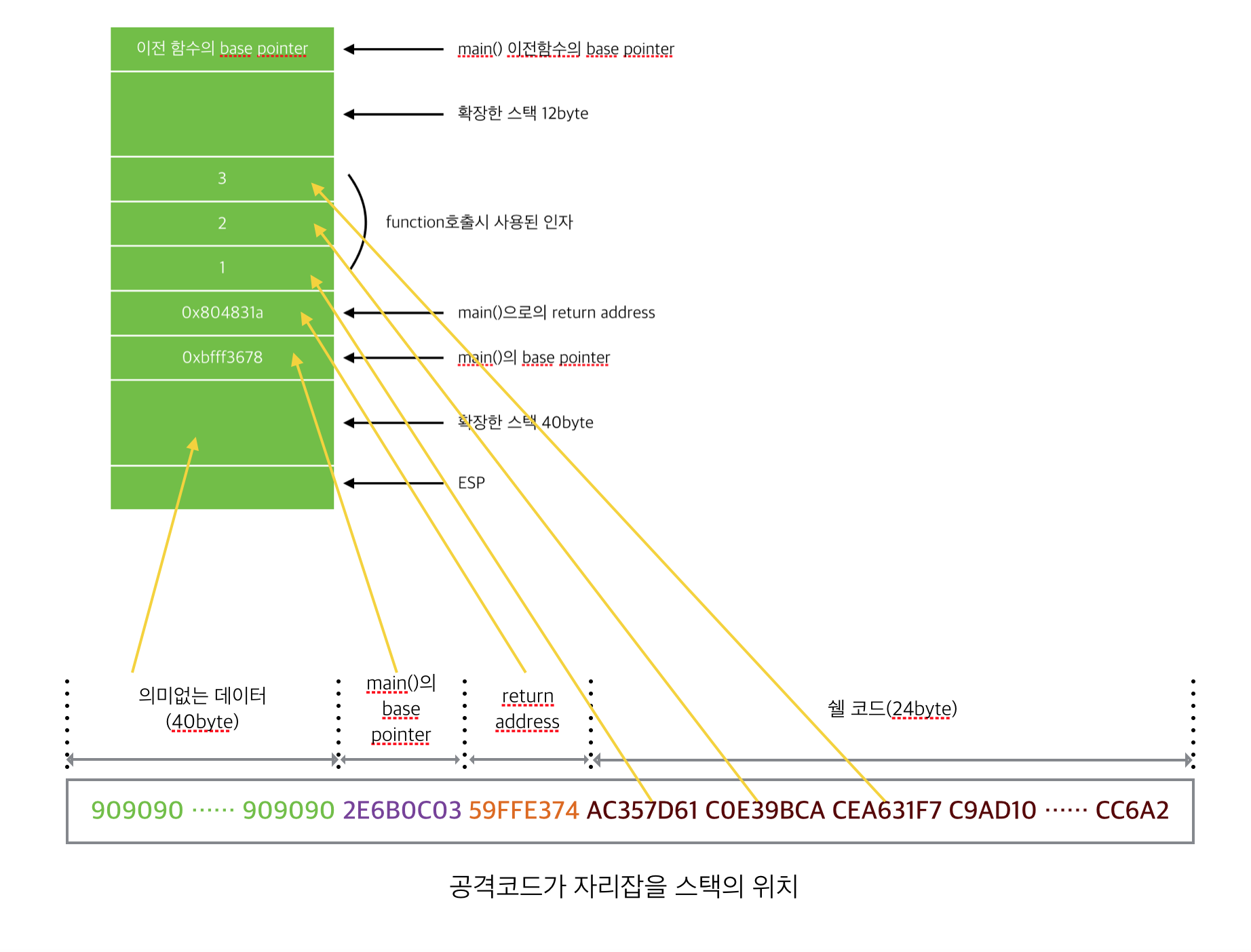
strcpy가 호출되고 나면 스텍 안의 데이터터는 아래와 같다.

이것은 receive_from_client의 데이터를를 버퍼에 복사한 후의 모습이다.
데이터와 순서에 있어서 차이가 있는걸 확인 할 수 있다.
Byte order
데이터가 저장되는 순서가 바뀐 이유는 바이트 정렬 방식이다.
현존하는 시스템들은 두 가지의 바이트 순서(byte order)를 가지는데 이는 big endian 방식과 little endian 방식이 있다.
big endian 방식은 높은 메모리 주소에서 낮은 메모리 주소로 되어있다.
IBM 370컴퓨터와 RISC 기반의 컴퓨터들 그리고 모토로라의 마이크로프로세서는 big endian 방식으로 정렬하고 그 외의 일반적인 IBM 호환 시스템, 알파 칩의 시스템들은 모두 little endian 방식을 사용한다.
EX)
74E3FF59 라는 값을 저장한다면
big endian에서는 (낮은 메모리 영역부터 값을 채워 나가서)
74E3FF59
little endian에서는
59FFE374
이 된다.
little endian이 저장 순서를 뒤집어 놓은 이유는 수를 더하거나 빼는 셈을 할 때 낮은 메모리 주소 영역의 변화는 수의 크기 변화에서 더 적기 때문이다.
Ex)
74E3FF59에 1을 더한다고 하면
74E3FF5A가 될 것이고 메모리상에서의 변화는
5AFFE374가 된다.
즉 낮은 수의 변화는 낮은 메모리 영역에 영향을 받고 높은 수의 변화는 높은 메모리 영역에 자리를 잡게 하겠다고 하는 것이 little endian 방식의 논리이다.
높은 메모리에 있는 바이트가 변하면 수의 크기는 크게 변한다는 말이다.
하지만 한 바이트 내에서 bit의 순서는 big endian 방식으로 정렬된다.
(참고로 네트윅 byte order는 big endian 방식을 사용한다.)
이러한 byte order의 문제 때문에 공격 코드의 바이트를 정렬할 때에는 이러한 문제점을 고려해야한다.
다시 위의 strcpy가 호출되고 나서로 돌아가면
return address가 변경 되었고 실제 명령이 들어 있는 코드는 그 위에 있다. 이 시점까지는 아무런 에러를 발생하지 않을 것이다. 하지만 함수 실행이 끝나고 ret instruction을 만나면 return address가 있는 위치의 값을 EIP에 넣을 것이고 이제 EIP가 가리키는 곳의 명령을 수행하려 할 것이다. 이 때 이 주소에 명령어가 들어 있지 않다면 프로그램은 오류를 발생시키게 된다. 또한 공격자는 자신이 만든 공격 코드를 실행하기를 원하므로 EIP에 return address 위에 있는 쉘 코드의 시작 주소를 넣고 싶어 한다.
일단은 쉘 코드가 들어있는 지점의 정확한 주소를 찾았다고 가정한다.
앞의 예제를 참고 할 때, 주소는 0xbfffe660이다.
이를 다시 그려 쉘 코드와 return address를 묘사해보면 다음과 같다.
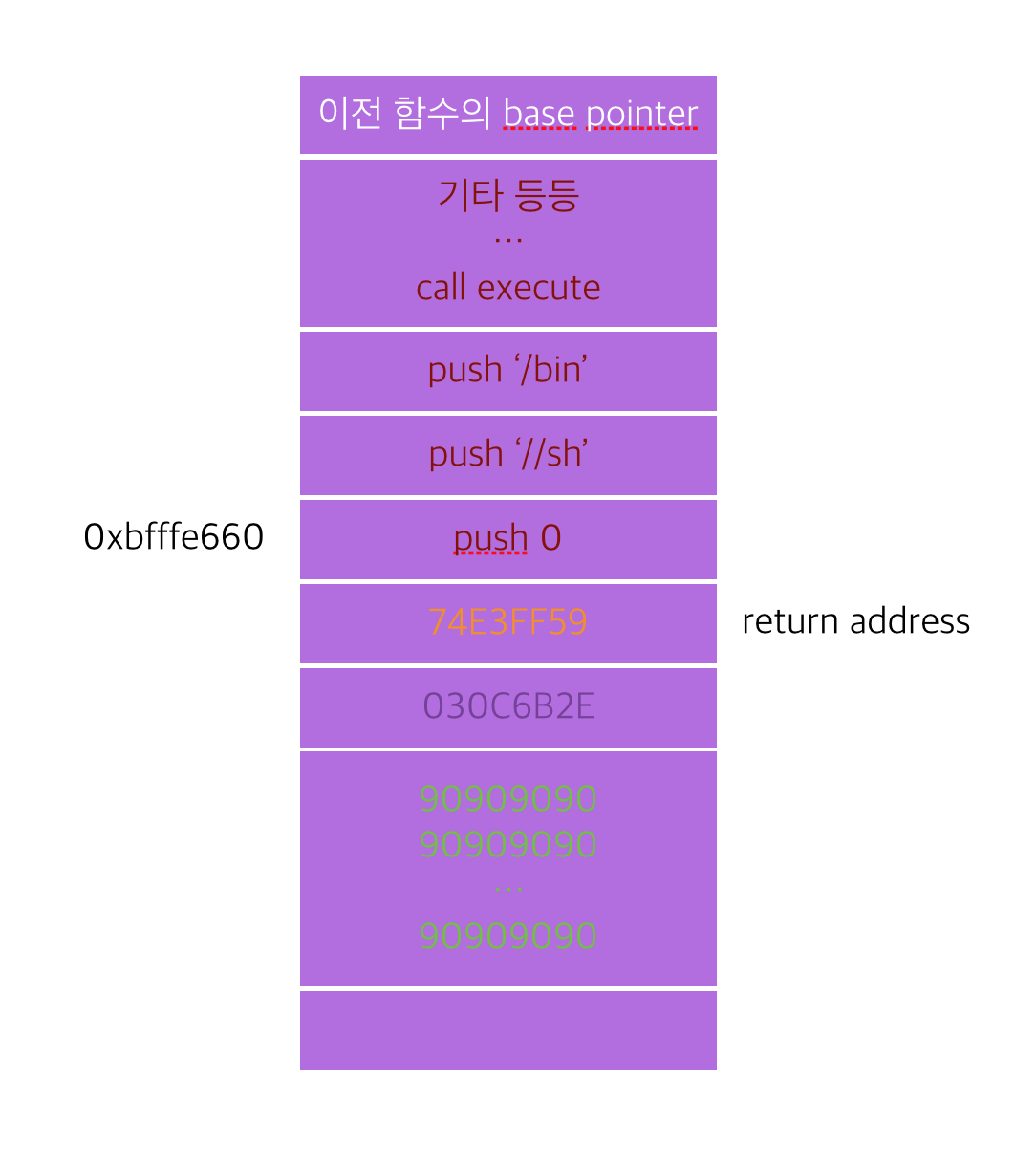
여기서 보여주는 공격 코드는 execve(“/bin/sh”, ...)이다.
즉 쉘을 띄우는 것이다.
실제 쉘 코드가 위의 그림처럼 들어가 있는 것은 아니다. 쉘 코드를 기계어 코드로 변환하여 1 word 단위로 넣어가면서 따져보면 알 수 있겠으나 저 위치에 저런 의ㅣ의 코드가 들어있다는 개념을 표현한 것이므로 그 개념만 이해하면 된다.
쉘 코드의 시작 지점은 스텍상의 0xbfffe660이다. 따라서 함수가 리턴될 때 return address는 EIP에 들어가게 될 것이고 EIP는 0xbfffe660에 있는 명령을 수행할 것이므로 execve(“/bin/sh”,...)를 수행하게 된다.
이것이 바로 buffer overflow를 이용한 공격방법이다.
문제점
위의 그림에서 공격 코드는 총 24byte 공간 안에 들어가 있다. 하지만 공격 코드가 24byte로 만들어 진다면 좋겠지만 그렇지 못할 경우가 발생할 수 있다. 즉 return address위의 버퍼 공간이 쉘 코드를 넣을 만큼 충분하지 않다면 다른 공간을 찾아보는 수 밖에 없다. 위의 예에서 사용할 수 있는 공간은 바로 90909090... 이 들어가 있는 function()함수가 사용한 스텍 공간이다. 이 공간은 40byte이고 추가로 main()함수의 bp가 저장되어 있는 4byte까지 무려 44byte라는 공간이 낭비되고 있다. 그래서 비좁은 24pyte의 공간이 아니라 20byte나 더 넓은 저 공간을 활용해 보자.
그러면 문제는 return address가 EIP에 들어간 다음에 40byte의 스텍 공간의 명령을 수행할 수 있도록 해주어야 한다.
물론 return address에다 직접 40byte공간의 주소를 적어주면 좋겠지만 위에서 언급 했듯이 해당 명령어가 있는 주소를 정확히 알아내는 것은 매우 어렵다. 따라서 간접적으로 그 곳으로 명령 수행 지점을 변경해 주는 방법을 사용한다.
다음 그림은 ESP값을 이용하여 명령 수행 지점을 지정해 주는 방법을 보여준다.

쉘 코드가 return address 아래에 있다.
즉 40byte가 남아 있던 그 공간이다. return address는 똑 같다.
함수가 실행을 마치고 return할 때 return address가 스텍에서 POP되어 EIP에 들어가고 나면 stack pointer는 1 word 위로 이동한다. 따라서 ESP는 return address가 있던 자리 위를 가리키게 된다. EIP는 0xbfffe660을 가리키고 있을 테니 그 곳에 있는 명령을 수행할 것이다.
쉘 코드가 있던 그 자리에서 다음과 같은 코드가 들어갔다. ESP가 가리키는 지점을 쉘 코드가 있는 위치를 가리키도록 48byte를 빼 주고 jmp %esp instruction을 수행하여 EIP에 ESP가 가리키는 지점의 주소를 넣도록 한다. 이 과정의 명령들을 쉘 코드로 변환했을 때 단 8byte만 있으면 충분하다. 다행히도 eSP 레지스터는 사용자가 직접 수정할 수 있는 레지스터이기 때문에 가능해진다.
위에서는 return address 이후의 버퍼 공간이 부족할 경우 return address 이전의 버퍼 공간을 활용하는 방법을 설명하였다. 하지만 만약 이 공간도 부족하다면 return address 부분만을 제외한 위아래 모든 공간을 활용할 수 있을 것이고 그것도 안된다면 또다시 다른 공간을 찾는 작업을 해야한다.
참고 : 해커 지망생이 알아야할 bof 기초 -달고나
'Security > Pwnable' 카테고리의 다른 글
| Buffer Overflow 원리 - 공격-1 고전적인 방법 (0) | 2021.08.08 |
|---|---|
| Buffer Overflow 원리 - 쉘코드 (0) | 2021.08.06 |
| Buffer Overflow 원리 - 프로그램 구동시의 segment (2) (0) | 2021.08.06 |
| Buffer Overflow 원리 - 프로그램 구동시의 segment (1) (0) | 2021.08.06 |
| Buffer Overflow 원리 - 8086CPU 레지스터 구조 (0) | 2021.08.06 |



